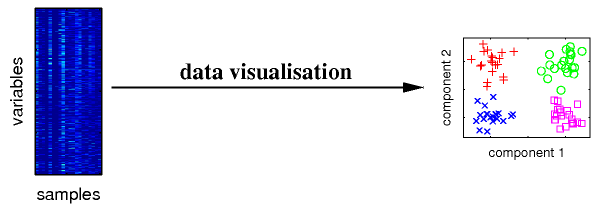
Example of how data clustering promotes clarity, from a PhD thesis by Matthias Scholtz
In many applications, data arrives in a constant stream, such as telephone records, multimedia data and financial transactions. In data streaming algorithms, the goal is to use a sequence of points to construct an accurate clustering of the given stream while being efficient with memory and time usage. Common components, version and heuristics for these algorithms include:
- CURE - especially good for non-uniform clusters and outliers by choosing a middle ground and shrinking scattered points toward it
- BIRCH - incrementally clusters incoming points by constructing a hierarchical data structure that minimizes input and output required
- STREAM - needs only a small space to achieve constant-factor approximation of the k-median problem in one pass
- COBWEB - incrementally clusters using a classification tree as its hierarchical clustering model
- C2ICM - selects objects as cluster seeds and assigns non-seed objects to the seed with the highest coverage to construct a flat partitioning cluster structure
To clarify the notation, k is an integer here where the input of the stream clustering is a sequence of points in metric space and k. The resulting output is called the K centers of that set of points where the sum of the distances from the data points themselves and the centers of the clusters is minimized. This notation gives popular cluster-analysis techniques like k-means and k-medoids clustering their names.
Clustering is important to do as it helps develop models and patterns from masses of seemingly patternless data. With the rise of data mining, the field has blossomed with research.
Icon credit EEPROM Eagle
© BrainMass Inc. brainmass.com June 29, 2026, 2:20 pm ad1c9bdddf